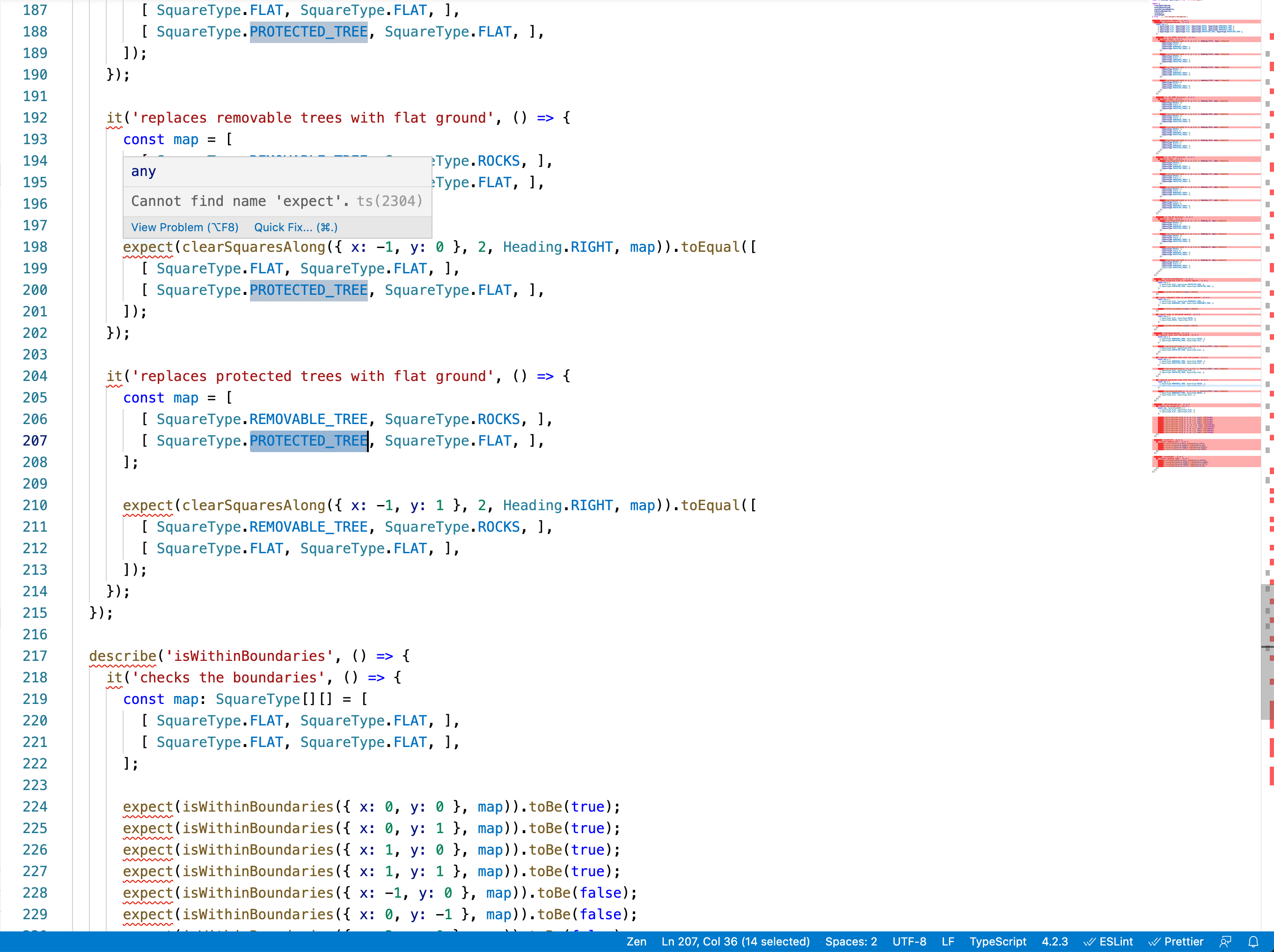
Experiment #1: mismatching type handling & error helpfulness
Contents
- Introduction
- Experiment 1, hex2rgb (you are here)
- Experiment 2, simple application
For a sake 🍶of science experiment, I have converted one function of a library I created long time ago to multiple languages that compile to JS and called it with various values.
The function is simple - it takes a color represented as a HEX string and converts it to { r, g, b } object.
The test is relatively big - it passes various numbers (integer and floating point, negative and positive), booleans, objects, arrays, obvious candidates - null and undefined and incorrect string.
The implementations are made with:
- Scala.js
- ReasonML
- ReScript
- F#
- PureScript
- TypeScript
- Elm
Implementations
Scala.JS
package darken_color
import scala.scalajs.js
import scala.scalajs.js.annotation._
class RGB(val r: Int, val g: Int, val b: Int) extends js.Object
@JSExportTopLevel("DarkenColor")
object DarkenColor {
@JSExport
def hex2rgb(s: String): RGB = {
val re = """^#?([0-9a-f]{2})([0-9a-f]{2})([0-9a-f]{2})$""".r
val rgbStr = s match {
case re(rStr, gStr, bStr) => Some((rStr, gStr, bStr))
case _ => None
}
rgbStr.map (x => new RGB(Integer.parseInt(x._1, 16), Integer.parseInt(x._2, 16), Integer.parseInt(x._3, 16))).getOrElse(null)
}
}ReasonML
type rgb = {
r: int,
g: int,
b: int,
}
let parse_hex = s => int_of_string("0x" ++ s)
let hex2rgb = hex =>
Js.Re.fromString("^#?([a-f0-9]{2})([a-f0-9]{2})([a-f0-9]{2})$")
-> Js.Re.exec_(hex)
-> Belt.Option.map (Js.Re.captures)
-> Belt.Option.map (Js.Array.map (Js.Nullable.toOption))
-> Belt.Option.map (x => Js.Array.sliceFrom(1, x))
-> Belt.Option.map (Js.Array.map (x => Belt.Option.map(x, parse_hex)))
-> (matches => switch matches {
| Some([ Some(r), Some(g), Some(b) ]) => Some({ r: r, g: g, b: b })
| _ => None
})ReScript
type rgb = {
r: int,
g: int,
b: int,
}
let parse_hex = s => Int.fromString("0x" ++ s, ~radix=16)
let hex2rgb = hex =>
RegExp.fromString("^#?([a-f0-9]{2})([a-f0-9]{2})([a-f0-9]{2})$")
->RegExp.exec(hex)
->Option.map(RegExp.Result.matches)
->Option.map(a => Array.slice(a, ~start=0))
->Option.map(a => Array.map(a, e => Option.flatMap(e, parse_hex)))
->Option.map(parsed =>
switch parsed {
| [Some(r), Some(g), Some(b)] => Some({r, g, b})
| _ => None
}
)PureScript
module DarkenColor where
import Prelude (join, map, ($), (<#>), (>>=), (>>>))
import Data.Array (catMaybes)
import Data.Array.NonEmpty (drop)
import Data.Int (fromStringAs, hexadecimal)
import Data.Maybe (Maybe(..))
import Data.Nullable (Nullable, toNullable)
import Data.Either (hush)
import Data.String.Regex (regex, match)
import Data.String.Regex.Flags (ignoreCase)
type RGB =
{
r :: Int,
g :: Int,
b :: Int
}
constructRGB :: Array Int -> Maybe RGB
constructRGB [ r, g, b ] = Just { r: r, g: g, b: b }
constructRGB _ = Nothing
hex2rgb :: String -> Nullable RGB
hex2rgb hexString =
toNullable $
((hush >>> join) $ (regex "^#?([0-9a-f]{2})([0-9a-f]{2})([0-9a-f]{2})$" ignoreCase) <#> (\re -> (match re hexString)))
<#> (drop 1)
<#> catMaybes
<#> (map (fromStringAs hexadecimal))
<#> catMaybes
>>= constructRGBF#
module DarkenColor
open System.Text.RegularExpressions
type RGBType = { r: int16; g: int16; b: int16 }
let hex2rgb (hex: string) =
let m = Regex.Match(hex, "^#?([a-f0-9]{2})([a-f0-9]{2})([a-f0-9]{2})$")
if m.Success then
m.Groups
|> Seq.cast<Group>
|> Seq.skip 1 // zero capture group is always the full string, when it matches
|> Seq.map (fun m -> m.Value)
|> Seq.map (fun x -> System.Convert.ToInt16(x, 16))
|> Seq.toList
|> (function
| r :: g :: b :: [] -> Some { r = r; g = g; b = b }
| _ -> None)
else NoneTypeScript
interface RGBType {
r: number;
g: number;
b: number;
}
/**
* Converts a HEX color value to RGB by extracting R, G and B values from string using regex.
* Returns r, g, and b values in range [0, 255]. Does not support RGBA colors just yet.
*
* @param hex The color value
* @returns The RGB representation or {@code null} if the string value is invalid
*/
const hex2rgb = (hex: string): RGBType => {
// Expand shorthand form (e.g. "03F") to full form (e.g. "0033FF")
const shorthandRegex = /^#?([a-f\d])([a-f\d])([a-f\d])$/i;
hex = hex.replace(shorthandRegex, (_match, r, g, b) => {
return r + r + g + g + b + b;
});
const result = /^#?([a-f\d]{2})([a-f\d]{2})([a-f\d]{2})$/i.exec(hex);
if (!result) {
return undefined;
}
return {
r: parseInt(result[1], 16),
g: parseInt(result[2], 16),
b: parseInt(result[3], 16)
};
}
export { hex2rgb };Elm
module DarkenColor exposing (..)
import List
import Maybe
import Maybe.Extra
import Regex
type alias RGBType = { r: Int, g: Int, b: Int }
hex2rgb : String -> Maybe RGBType
hex2rgb hex =
Regex.fromString "^#?([a-f0-9]{2})([a-f0-9]{2})([a-f0-9]{2})$"
|> Maybe.map (\regex -> Regex.find regex hex)
|> Maybe.map (List.map .match)
|> Maybe.map (List.map String.toInt)
|> Maybe.andThen (Maybe.Extra.combine)
|> Maybe.andThen constructRGB
constructRGB list =
case list of
[ r, g, b ] -> Maybe.Just { r = r, g = g, b = b }
_ -> Maybe.NothingFor fair comparison, the implementation is kept same (no platform-specific code, except Option in functional languages) and every single bundle is processed with Webpack 4.
The test checks both the result and the assumes no exception is thrown, even when the input is incorrect. For the interest sake, the exceptions thrown as well as bundle sizes will be listed below.
Gleam
A naive implementation:
import gleam/int
import gleam/list
import gleam/option.{Some}
import gleam/regexp.{Match}
import gleam/result
pub type RGB {
RGB(r: Int, g: Int, b: Int)
}
pub fn hex2rgb(color: String) -> RGB {
let assert Ok(re) = from_string("^#?([0-9a-f]{2})([0-9a-f]{2})([0-9a-f]{2})$")
let assert [
Match(content: _, submatches: [Some(r_str), Some(g_str), Some(b_str)]),
] = scan(with: re, content: color)
let assert [Ok(r), Ok(g), Ok(b)] = [
base_parse(r_str, 16),
base_parse(g_str, 16),
base_parse(b_str, 16),
]
RGB(r, g, b)
}This produces approximately 8 KB bundle, but this implementation treats any error as a panic.
An implementation which handles the errors properly looks somewhat like this:
pub fn hex2rgb(color: String) {
use re <- result.try(
result.try_recover(
regexp.from_string("^#?([0-9a-f]{2})([0-9a-f]{2})([0-9a-f]{2})$"),
fn(_) { Error("can not parse regexp pattern") },
),
)
use rgb_strs <- result.try(case regexp.scan(re, color) {
[Match(content: _, submatches: [Some(r_str), Some(g_str), Some(b_str)])] ->
Ok([r_str, g_str, b_str])
_ -> Error("can not match components of a regexp")
})
let parse_res =
result.all(list.map(rgb_strs, fn(x) { int.base_parse(x, 16) }))
use rgb <- result.try(
result.try_recover(parse_res, fn(_) { Error("can not parse hex numbers") }),
)
case rgb {
[r, g, b] -> Ok(RGB(r, g, b))
_ -> Error("can not find three integer color components")
}
}Unfortunately, this one is a bit larger at 10 KB.
An idiomatic Gleam implementation would make use of separate helper functions:
fn parse_color(color: String) {
use re <- result.try(
result.map_error(
regexp.from_string("^#?([0-9a-f]{2})([0-9a-f]{2})([0-9a-f]{2})$"),
fn(_) { "can not parse regexp pattern" },
),
)
case regexp.scan(re, color) {
[Match(content: _, submatches: [Some(r_str), Some(g_str), Some(b_str)])] ->
Ok(#(r_str, g_str, b_str))
_ -> Error("can not match components of a regexp")
}
}
fn parse_hex(input: String) {
result.map_error(int.base_parse(input, 16), fn(_) {
"can not parse " <> input <> " as hexadecimal number"
})
}
pub fn hex2rgb(color: String) {
use #(r_str, g_str, b_str) <- result.try(parse_color(color))
use r <- result.try(parse_hex(r_str))
use g <- result.try(parse_hex(g_str))
use b <- result.try(parse_hex(b_str))
Ok(RGB(r, g, b))
}This implementation is the smallest of the bunch at 8.7 KB and as an added bonus, passes all the tests (unlike the previous implementations - in Gleam, that is).