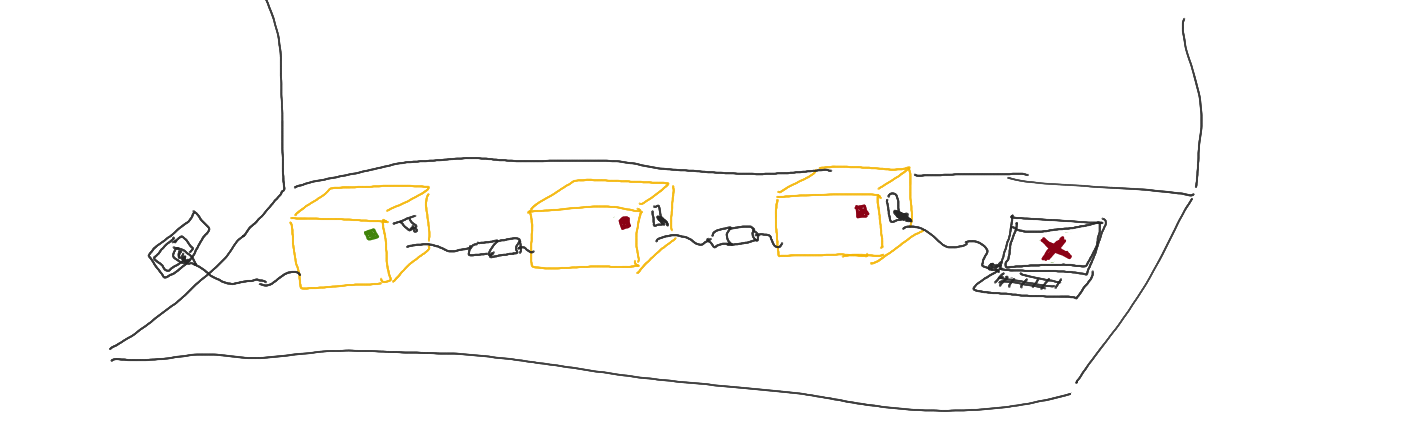
As promised in my previous blog about Erlang, I continue
on a journey to more practical Erlang examples.
This might sound super ambitious, but let us build a distributed database.
For sake of simplicity, let’s make it a reduced version of Redis - a key-value distributed in-memory storage.
Essentially, an over-engineered hashmap.
To draw some boundaries around this, let’s focus on these key features:
- simple CRUD actions - get, set and delete a value; this should operate on REST-like API:
get(<key>) - get key valueset(<key>) - use request body for value and associate the value with the keydelete(<key>) - remove the key from the storage
- running on multiple nodes (machines)
- synchronizing the data between the nodes; this should support:
- ability to rotate the nodes in the cluster (switch off nodes and add new ones randomly) without the loss of data
- distributing the operations across the nodes to keep the data in sync
Sounds unbelievable, but with Erlang this is actually pretty simple.
Erlang is actually a great choice for an application like this, since we do not have to worry about setting up the cluster
and deal with communication protocols (as in how to pass data over the network between the nodes).
We will need a “main” process, which will take the requests from the users and pass them to the nodes.
Each node will store its own copy of the data in memory. On startup, each new node will receive the copy of the data
from the first available node. If no nodes are available - that means the cluster is fresh and we can safely assume
the data is empty (or the cluster has died altogether and that state is unrecoverable).
Step 1: draw a circle
Start simple: let us have a simple application which starts a background process and responds to some commands.
It could be as simple as ping - pong application - the background process waits for a ping message and responds with pong
upon receiving one.
-module(db_server).
-export([start/0, stop/0, ping/0]).
start() ->
Pid = spawn_link(fun () -> loop() end),
register(server, Pid),
ok.
stop() ->
server ! stop,
ok.
ping() ->
server ! { ping, self() },
receive
pong -> pong
end.
loop() ->
receive
{ ping, Pid } ->
Pid ! pong,
loop();
stop -> ok
end.
This is a relatively simple application, but it has few quirks:
spawn_link/1 (spawn_link(loop)) - this function spawns a new background process and links it to the current one, so that once the current process stops, the linked process also stopsregister/2 (register(server, Pid)) - registers a global (in the current module scope) symbol (server in this case) and associates it with the process PID passed as the second parameter (Pid in this case, the PID of the spawned process running the loop function)- the
ping/0 function sends a message ({ ping, self() } tuple) containing the atom ping and current process’ PID to the process registered as server; it then starts waiting for any process to send a pong message to the current process, effectively blocking the current process until that message is received
- the
loop function responds to two messages:
{ ping, Pid } - by sending pong message to the process with PID set in the Pid constant and running itself recursively (turning the entire loop/0 function into a while loop)stop - by simply returning the ok atom and exiting (thus terminating the loop)
To run this application, start the Erlang shell with erl and type in few prompts:
1> c(db_server).
{ok,db_server}
2> db_server:start().
ok
3> db_server:ping().
pong
The benefit of this architecture is that once we have an Erlang shell open and run the start/0 function, it will start the background process and exit immediately. But the background process will keep running and we will have the other functions available to interact with that process, without loosing the access to the Erlang shell.
This protocol also highlights the concurrent aspect of the application - we send the current process’ PID to the callee and start listening for the messages from anywhere.
Once we receive the message - we pass it to the other process. So the entire application is predominantly non-blocking and asynchronous in nature.
Step 2: draw a second circle
The application is surely awesome, but let’s make it actually useful to any extent. We are designing a key-value storage, so why not to have one?
Instead of just reacting to the ping message, we can have a map and have a simple API to set value, get value and delete a value from the map while
keeping the map on the child process.
-module(db_server).
-export([ start/0, stop/0 ]).
-export([ get/1, set/2, delete/1 ]).
start() ->
Pid = spawn_link(fun () -> loop(maps:new()) end),
register(server, Pid),
ok.
stop() ->
server ! stop,
ok.
set(Key, Value) ->
server ! { set, Key, Value },
ok.
get(Key) ->
server ! { get, Key, self() },
receive
{ get, Value } -> Value
end.
delete(Key) ->
server ! { delete, Key },
ok.
loop(Data) ->
receive
{ set, Key, Value } ->
NewData = maps:put(Key, Value, Data),
loop(NewData);
{ get, Key, Pid } ->
Pid ! { get, maps:get(Key, Data, none) },
loop(Data);
{ delete, Key } ->
NewData = maps:remove(Key, Data),
loop(NewData);
stop -> ok
end.
As you can see, there’s nothing special going on here - all is quite simple. We start the background process with some initial data (maps:new())
and in the loop/1 function whenever we enter recursion, we pass the new version of the data to the recursive call.
The only function which actually is blocking its execution until it receives a response from a callee is get/1 - we wait for the background process
to send the value to the current process.
The interaction with this application could look like this:
1> c(db_server).
{ok,db_server}
2> db_server:start().
ok
3> db_server:set(moo, -3.14).
ok
4> db_server:get(moo).
-3.14
5> db_server:delete(moo).
ok
6> db_server:get(moo).
none
Step 3: draw the rest of the owl
Now for the juicy bits: let us have a worker node, which will actually be a replica of the database.
It is as simple as extracting the logic from loop/1 function to a separate module and having a new process being started
on a new node, once we decide to add it to the cluster:
-module(worker).
-export([ loop/1 ]).
loop(Data) ->
receive
{ set, Key, Value } ->
NewData = maps:put(Key, Value, Data),
loop(NewData);
{ get, Key, Pid } ->
Pid ! { get, maps:get(Key, Data, none) },
loop(Data);
{ delete, Key } ->
NewData = maps:remove(Key, Data),
loop(NewData);
stop -> ok
end.
The db_server module needs few changes:
-module(db_server).
-export([ start/0, stop/0 ]).
-export([ get/1, set/2, delete/1 ]).
-export([ add_node/1 ]).
start() ->
Pid = spawn_link(fun () -> loop([]) end),
register(server, Pid),
ok.
stop() ->
server ! stop,
ok.
set(Key, Value) ->
server ! { set, Key, Value },
ok.
get(Key) ->
server ! { get, Key, self() },
receive
{ get, Value } -> Value
end.
delete(Key) ->
server ! { delete, Key },
ok.
add_node(NodeAddr) ->
server ! { add_node, NodeAddr },
ok.
loop(Nodes) ->
receive
{ set, Key, Value } ->
lists:foreach(fun ({ _, NodePid }) -> NodePid ! { set, Key, Value } end, Nodes),
loop(Nodes);
{ get, Key, Pid } ->
[{ _, FirstNodePid }|_] = Nodes,
FirstNodePid ! { get, Key, Pid },
receive
{ get, Value } -> Pid ! { get, Value }
end,
loop(Nodes);
{ delete, Key } ->
lists:foreach(fun ({ _, NodePid }) -> NodePid ! { delete, Key } end, Nodes),
loop(Nodes);
{ add_node, NodeAddr } ->
Data = maps:new(),
NodePid = spawn(NodeAddr, worker, loop, [ Data ]),
monitor(process, NodePid),
NewNodes = lists:append([ { NodeAddr, NodePid } ], Nodes),
loop(NewNodes);
stop -> ok
end.
The public API of the db_server module does not really change - there’s a new function add_node/1 but that’s about it - these
exported (aka “public”) functions only send messages to the server process.
The loop/1 function on the other hand has most changes - instead of sending message to a single process, it now distributes them
across the processes stored in the Nodes constant. This constant is a list of tuples { NodeAdd, NodePid } where the NodeAddr
(the first element of the tuple) is just to keep track of nodes added to the list (for debug purposes predominantly) and NodePid
(the second element of the tuple) is what is actually used to communicate with the db_server process.
All the control messages (get, set and delete) are passed to all nodes from the Nodes list.
Exception being the { get, Key, Pid } message - it only sends the message to the first node from the list.
And since all the worker nodes are (supposed to be) just replicas of each other, it is sufficient.
So far this should work. Start the db_server node with
$ erl -sname supervisor
followed by the call to
(supervisor@MACHINENAME)> c(db_server).
{ok,db_server}
(supervisor@MACHINENAME)> db_server:start().
ok
Then, add few nodes to the cluster. For that, the node must be running and must use the same naming convention as the supervisor
(short name, set with -sname param to the erl or long name, set with the -name param to the erl) - otherwise they won’t see each other.
$ erl -sname subnode1
followed by
(subnode1@MACHINENAME)> c(worker).
{ok,worker}
Note how you don’t need to do anything on the worker node except compile the module. The supervisor node will start processes on that node itself.
Lastly, on the server node call
(supervisor@MACHINENAME)> server:add_node(subnode1@MACHINENAME).
ok
The node name is printed out to the Erlang shell once you start erl with -sname or -name param provided.
But you can also add io:format("Started node at ~s~n", node()) as the first statement in the loop/1 function in worker module -
it will print out the node name to the Erlang shell once the function is started. You can then use it as a raw atom parameter to server:add_node/1.
Now, the last piece to the system is keeping all the worker nodes in sync by copying the data from the first alive node to the new node once it is added
to the supervisor.
To do so, we will need to utilize the net_adm module, which conveniently has the net_adm:ping/1 function, taking the node address and returning pond
atom if the node is alive and is visible from the current node or pang otherwise.
This way we can replace all the occurrences of the Nodes list in the db_server:loop/1 function with the list of alive nodes:
% supervisor
loop(Nodes) ->
AliveNodes = sets:filter(fun ({ NodeAddr, _ }) -> net_adm:ping(NodeAddr) == pong end, Nodes),
receive
{ set, Key, Value } ->
lists:foreach(fun ({ _, NodePid }) -> NodePid ! { set, Key, Value } end, AliveNodes),
loop(AliveNodes);
{ get, Key, Pid } ->
[ { _, FirstNodePid } | _ ] = AliveNodes,
FirstNodePid ! { get, Key, Pid },
receive
{ get, Value } -> Pid ! { get, Value }
end,
loop(AliveNodes);
{ delete, Key } ->
lists:foreach(fun ({ _, NodePid }) -> NodePid ! { delete, Key } end, AliveNodes),
loop(AliveNodes);
{ add_node, NodeAddr } ->
Data = maps:new(),
NodePid = spawn(NodeAddr, worker, loop, [ Data ]),
monitor(process, NodePid),
NewNodes = lists:append([ { NodeAddr, NodePid } ], AliveNodes),
loop(NewNodes);
stop -> ok
end.
Now to get the data from the node, we will need an extra message to be supported by the worker module:
% worker
loop(Data) ->
receive
{ set, Key, Value } ->
NewData = maps:put(Key, Value, Data),
loop(NewData);
{ get, Key, Pid } ->
Pid ! { get, maps:get(Key, Data, none) },
loop(Data);
{ delete, Key } ->
NewData = maps:remove(Key, Data),
loop(NewData);
{ get_all, Pid } ->
Pid ! { get_all, Data },
loop(Data);
stop -> ok
end.
This way when we want to add a new node to the cluster, we will need to first get the data from the first available node
and then send it to the newly added node in the db_server module. But if there are no nodes alive, we want the maps:new() to be the new data:
% supervisor
loop(Nodes) ->
AliveNodes = lists:filter(fun ({ NodeAddr, _ }) -> net_adm:ping(NodeAddr) == pong end, Nodes),
receive
{ set, Key, Value } ->
lists:foreach(fun ({ _, NodePid }) -> NodePid ! { set, Key, Value } end, AliveNodes),
loop(AliveNodes);
{ get, Key, Pid } ->
[ { _, FirstNodePid } | _ ] = AliveNodes,
FirstNodePid ! { get, Key, Pid },
receive
{ get, ReceivedValue } -> ReceivedValue
end,
Pid ! { get, Value },
loop(AliveNodes);
{ delete, Key } ->
lists:foreach(fun ({ _, NodePid }) -> NodePid ! { delete, Key } end, AliveNodes),
loop(AliveNodes);
{ add_node, NodeAddr } ->
Data = case AliveNodes of
[ { _, FirstNodePid } | _ ] ->
FirstNodePid ! { get_all, self() },
receive
{ get_all, NewData } -> NewData;
_ -> maps:new()
end;
_ -> maps:new()
end,
NodePid = spawn(NodeAddr, worker, loop, [ Data ]),
monitor(process, NodePid),
NewNodes = lists:append([ { NodeAddr, NodePid } ], AliveNodes),
loop(NewNodes);
stop -> ok
end.
You may practice putting nodes on and off the running cluster, getting and setting the values at the same time.
But occasionally you might stumble upon a db_server:get/1 function hanging.
This is what happens when there are no alive nodes on the cluster.
In order to fix this, we can simply add a check for that instead of blindly taking the first node from the AliveNodes list:
% supervisor
loop(Nodes) ->
AliveNodes = lists:filter(fun ({ NodeAddr, _ }) -> net_adm:ping(NodeAddr) == pong end, Nodes),
receive
{ set, Key, Value } ->
lists:foreach(fun ({ _, NodePid }) -> NodePid ! { set, Key, Value } end, AliveNodes),
loop(AliveNodes);
{ get, Key, Pid } ->
Value = case AliveNodes of
[ { _, FirstNodePid } | _ ] ->
FirstNodePid ! { get, Key, self() },
receive
{ get, ReceivedValue } -> ReceivedValue
end;
_ -> no_nodes
end,
Pid ! { get, Value },
loop(AliveNodes);
{ delete, Key } ->
lists:foreach(fun ({ _, NodePid }) -> NodePid ! { delete, Key } end, AliveNodes),
loop(AliveNodes);
{ add_node, NodeAddr } ->
Data = case AliveNodes of
[ { _, FirstNodePid } | _ ] ->
FirstNodePid ! { get_all, self() },
receive
{ get_all, NewData } -> NewData;
_ -> maps:new()
end;
_ -> maps:new()
end,
NodePid = spawn(NodeAddr, worker, loop, [ Data ]),
monitor(process, NodePid),
NewNodes = lists:append([ { NodeAddr, NodePid } ], AliveNodes),
loop(NewNodes);
stop -> ok
end.
This will still not work however. The issue is that we only assign the value to the AliveNodes once we enter the db_server:loop/1 function.
And that only happens after it processed a message. But the moment the value is actually needed is right before processing a message.
See the difference? There might be a delay between processing (as in “receiving”) a message and figuring the list of actually alive nodes because
the process is blocked waiting for new messages.
One way to fix this is to move the AliveNodes assignment to each branch of the receive block:
% supervisor
loop(Nodes) ->
receive
{ set, Key, Value } ->
AliveNodes = lists:filter(fun ({ NodeAddr, _ }) -> net_adm:ping(NodeAddr) == pong end, Nodes),
lists:foreach(fun ({ _, NodePid }) -> NodePid ! { set, Key, Value } end, AliveNodes),
loop(AliveNodes);
{ get, Key, Pid } ->
AliveNodes = lists:filter(fun ({ NodeAddr, _ }) -> net_adm:ping(NodeAddr) == pong end, Nodes),
Value = case AliveNodes of
[ { _, FirstNodePid } | _ ] ->
FirstNodePid ! { get, Key, self() },
receive
{ get, ReceivedValue } -> ReceivedValue
end;
_ -> no_nodes
end,
Pid ! { get, Value },
loop(AliveNodes);
{ delete, Key } ->
AliveNodes = lists:filter(fun ({ NodeAddr, _ }) -> net_adm:ping(NodeAddr) == pong end, Nodes),
lists:foreach(fun ({ _, NodePid }) -> NodePid ! { delete, Key } end, AliveNodes),
loop(AliveNodes);
{ add_node, NodeAddr } ->
AliveNodes = lists:filter(fun ({ NodeAddr, _ }) -> net_adm:ping(NodeAddr) == pong end, Nodes),
Data = case AliveNodes of
[ { _, FirstNodePid } | _ ] ->
FirstNodePid ! { get_all, self() },
receive
{ get_all, NewData } -> NewData;
_ -> maps:new()
end;
_ -> maps:new()
end,
NodePid = spawn(NodeAddr, worker, loop, [ Data ]),
monitor(process, NodePid),
NewNodes = lists:append([ { NodeAddr, NodePid } ], AliveNodes),
loop(NewNodes);
stop -> ok
end.
Alternatively, we can utilize the after keyword which effectively implements a timeout mechanism:
% supervisor
loop(Nodes) ->
receive
{ set, Key, Value } ->
lists:foreach(fun ({ _, NodePid }) -> NodePid ! { set, Key, Value } end, Nodes),
loop(Nodes);
{ get, Key, Pid } ->
Value = case Nodes of
[ { _, FirstNodePid } | _ ] -> FirstNodePid ! { get, Key, self() },
receive
{ get, ReceivedValue } -> ReceivedValue,
_ -> none
end;
_ -> no_nodes
end,
Pid ! { get, Value },
loop(Nodes);
{ delete, Key } ->
lists:foreach(fun ({ _, NodePid }) -> NodePid ! { delete, Key } end, Nodes),
loop(Nodes);
{ add_node, NodeAddr } ->
Data = case Nodes of
[ { _, FirstNodePid } | _ ] ->
FirstNodePid ! { get_all, self() },
receive
{ get_all, NewData } -> NewData;
_ -> maps:new()
end;
_ -> maps:new()
end,
NodePid = spawn(NodeAddr, worker, loop, [ Data ]),
monitor(process, NodePid),
NewNodes = lists:append([ { NodeAddr, NodePid } ], Nodes),
loop(NewNodes);
stop -> ok
after
0 ->
AliveNodes = lists:filter(fun ({ NodeAddr, _ }) -> net_adm:ping(NodeAddr) == pong end, Nodes),
loop(AliveNodes)
end.
This will make the receive expression of the db_server:loop/1 function check if there are any messages in the internal message inbox (aka message queue)
associated with the current function. And if there are no messages after 0 (as in this case) time since the check started - the code in the corresponding
matching expression will be executed. In our scenario, we figure the new list of alive nodes and restart the loop function. This way the time the process
is sitting blocked waiting for messages is bare minimal.
On the other hand, if you look carefully at all those receive statements within the loop function, you might just notice… that you don’t need them
in fact - the worker nodes might just communicate with each other! So instead of sending self() PID to each worker node (for ex. for get message or get_all message),
you can just send the received node PID (which is a part of the message) to the worker node. This will make the code highly asynchronous:
% supervisor
loop(Nodes) ->
AliveNodes = lists:filter(fun ({ NodeAddr, _ }) -> net_adm:ping(NodeAddr) == pong end, Nodes),
receive
{ set, Key, Value } ->
lists:foreach(fun ({ _, NodePid }) -> NodePid ! { set, Key, Value } end, AliveNodes),
loop(AliveNodes);
{ get, Key, Pid } ->
case AliveNodes of
[ { _, FirstNodePid } | _ ] -> FirstNodePid ! { get, Key, Pid };
_ -> Pid ! { get, no_nodes }
end,
loop(AliveNodes);
{ delete, Key } ->
lists:foreach(fun ({ _, NodePid }) -> NodePid ! { delete, Key } end, AliveNodes),
loop(AliveNodes);
{ add_node, NodeAddr } ->
NodePid = spawn(NodeAddr, worker, loop, [ Data ]),
monitor(process, NodePid),
NewNodes = lists:append([ { NodeAddr, NodePid } ], AliveNodes),
case AliveNodes of
[ { _, FirstNodePid } | _ ] -> FirstNodePid ! { get_all, NodePid };
_ -> NodePid ! { got_all, maps:new() }
end,
loop(NewNodes);
stop -> ok
end.
This will need a tiny adjustment to the worker module (to support that { got_all, Data } messages), but the benefits are more than worth it!
% worker
loop(Data) ->
receive
{ set, Key, Value } ->
NewData = maps:put(Key, Value, Data),
loop(NewData);
{ get, Key, Pid } ->
Pid ! { get, maps:get(Key, Data, none) },
loop(Data);
{ delete, Key } ->
NewData = maps:remove(Key, Data),
loop(NewData);
{ get_all, Pid } ->
Pid ! { get_all, Data },
loop(Data);
{ got_all, NewData } ->
loop(NewData);
stop -> ok
end.
Wrap-up
The cherry on top of this cake would be to create an actual REST API (or any non-Erlang API for that matter) so that this database could be used
from the outside world without starting an Erlang shell. But I’d rather save it for a later blog.
For now you can actually plug and unplug nodes from the cluster, and while there is at least one node alive, the data integrity is guaranteed.
The highly asynchronous architecture of the solution allows for non-blocking calls all over the place.
For me, this is a great example on how to actually use Erlang!
The slightly built-up code is hosted on GitHub.